Your eval pipeline, automated on every deploy
Every prompt change, model swap, and guardrail update gets tested automatically. Fyntune runs your quality criteria and returns a verdict in under 90 seconds.
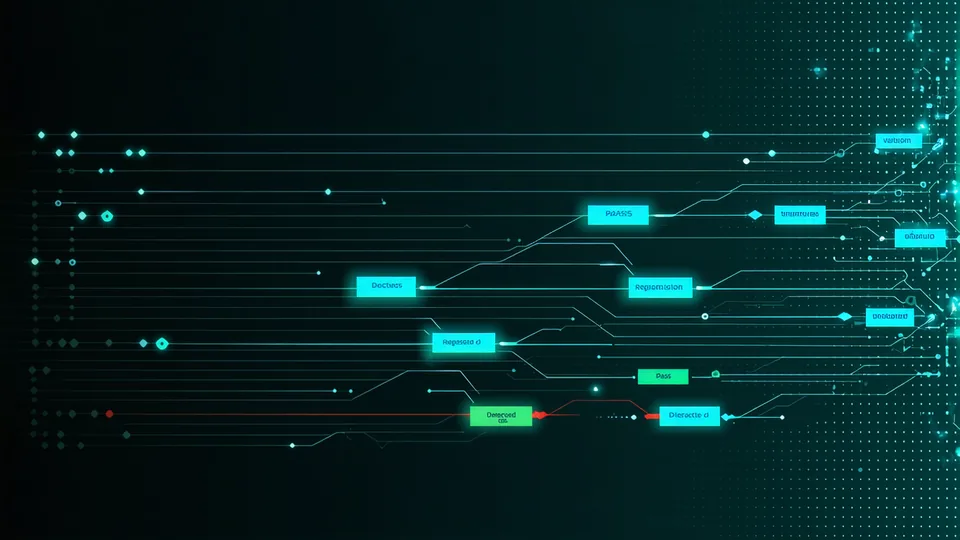
Code push to verdict in five steps
Fyntune sits inline with your deployment pipeline. No infrastructure changes needed.
Four eval types. Every deploy.
Semantic similarity, factuality, guardrail compliance, and LLM-as-judge — the four failure-mode categories that account for the vast majority of production LLM quality incidents we've seen across teams using Fyntune. Not a general-purpose testing framework: each type is purpose-built for the specific ways LLMs degrade when prompts or models change.
Output drift detection across prompt versions
Measures whether your LLM's outputs remain semantically consistent across prompt versions and model swaps. Not exact match — Fyntune computes cosine similarity against your golden dataset, so a response that conveys the same information in different words passes, while genuine content drift is flagged. Useful for detecting the slow factual drift that accumulates after successive prompt changes and doesn't show up in A/B test metrics until it's a support problem.
- Configurable similarity threshold per feature type
- Per-input breakdown, not just aggregate score
- Trend view across last 30 prompt versions
Catch hallucinations before they ship
Fyntune's factuality eval runs your LLM outputs against a reference set of verified facts. It flags responses that introduce incorrect claims or contradict source documents — the regression type most likely to generate support escalations.
- Ground-truth document comparison
- Claim-level flagging, not just sentence scoring
- Works with any LLM — no vendor lock-in
Silent guardrail failures, caught automatically
Guardrail regressions are the hardest to catch manually — they often only surface on edge-case inputs that aren't in your test set. Fyntune evaluates guardrail compliance across a statistically representative sample of your production input distribution on every release.
- Production input distribution sampling
- Custom guardrail rule definitions via YAML
- Outputs blocked from deploy on failure
Open-ended quality criteria, automated
Some quality dimensions — brand voice adherence, response completeness, appropriate hedging on uncertain claims — don't reduce to rule-based checks or cosine scores. Fyntune's LLM-as-judge evaluator lets you define criteria in plain language and uses a calibrated judge model to score outputs at scale. The judge model is independent of your production model and calibrated against your own human-labeled samples to minimize position bias and length preference errors common in off-the-shelf LLM-as-judge implementations.
- Custom criteria in plain language
- Calibration against human-labeled samples
- Judge model independence from production model
criteria:
- name: brand_voice
prompt: "Does the response maintain a professional,
direct tone without marketing language?"
threshold: 0.85
judge_model: claude-3-5-sonnet
- name: helpfulness
prompt: "Does the response directly address the
user's question with actionable information?"
threshold: 0.80Start catching regressions today
Free tier. Connect in under 15 minutes. No credit card required.